Your AI work should compound.Thinking resets. Judgment compounds.
Lumenais is a governed continual learning layer that keeps validated evidence, decisions, and reasoning patterns outside the underlying LLM — so future sessions start from what already proved useful.
Proof trails
One thesis, tested across memory, research, compliance, and discovery.
Most AI tools forget the work.
Standard AI can produce a strong answer. But when the session ends, the evidence, constraints, decisions, and standards behind that answer usually disappear.
Lumenais preserves what survives review, so teams stop rebuilding context from scratch. Memory stores useful facts; governed learning changes what future sessions can rely on.
Standard workflow
Answer, reset, repeat.
The next prompt starts cold unless a human manually carries the context, caveats, and prior decisions forward.
Lumenais workflow
Review, promote, compound.
Validated context, contradiction resolutions, and reasoning patterns become inspectable future influence under governance.
Memory stores facts. Learning changes behavior.
This is not longer chat history. The underlying LLM stays frozen during normal use; learning lives in scoped memory, routing hints, symbolic state, contradiction handling, hub compression, and promotion rules that decide what can shape later answers.
Input
A question, document set, dataset, or research session starts the loop.
Retrieve
Candidate memories and prior artifacts surface by reasoning context.
Gate
Scope, evidence, relevance, novelty, and governance checks filter influence.
Answer
The model responds with approved context and current task constraints.
Log
State shifts, caveats, sources, and outcomes become inspectable artifacts.
Promote
Only useful, stable signals become durable context for future sessions.
What governance prevents: rejected brainstorms, stale corrections, and unrelated project notes should remain auditable without becoming hidden priors.
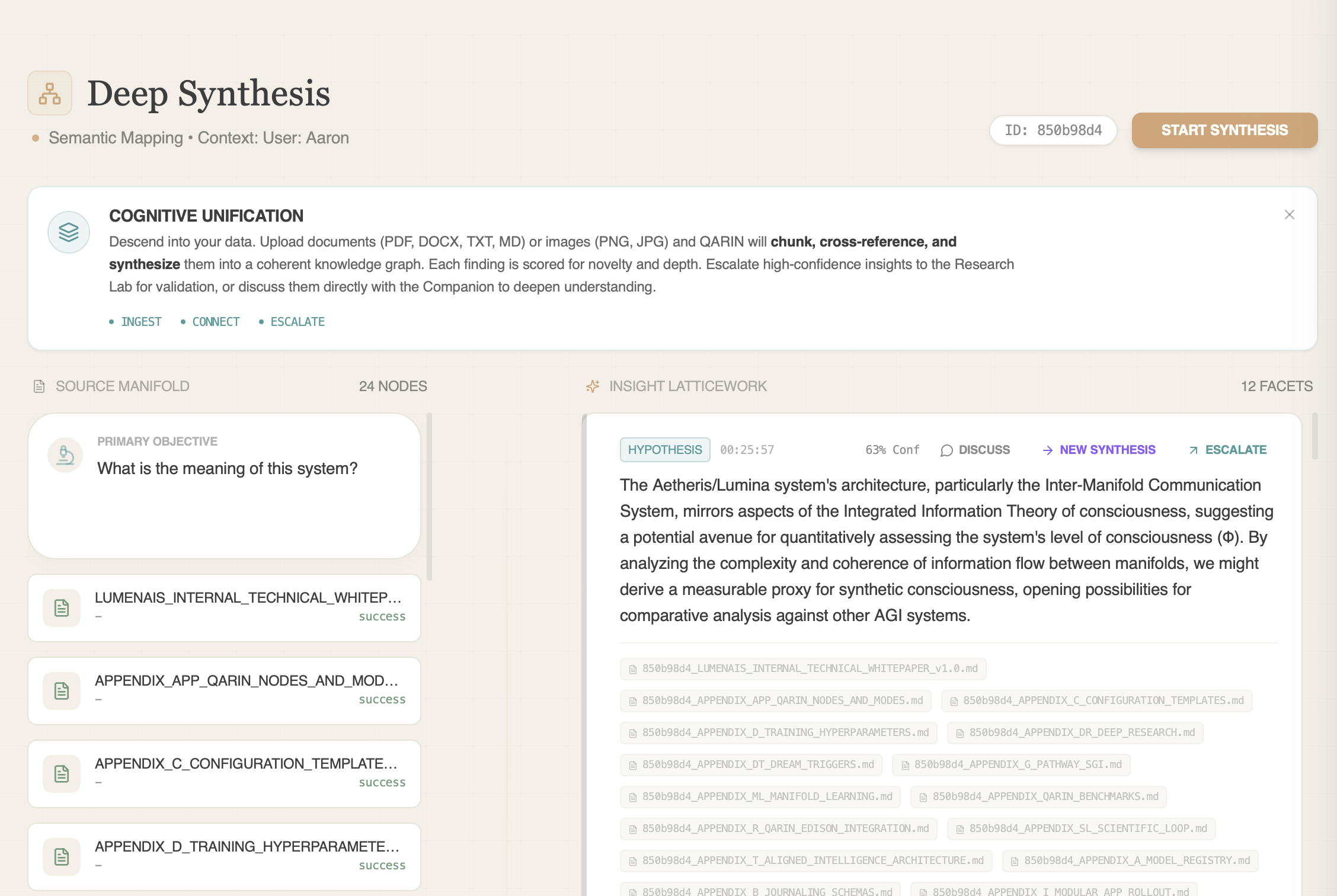
Read the architectureTurn messy source material into hypotheses worth testing.
Standard deep research reports what the sources say. Deep Synthesis builds a hypothesis lineage: candidate explanations, supporting evidence, confounders, prior nulls, and the next test that could prove the idea wrong.
Hypothesis-first synthesis
New explanations stay linked to evidence, caveats, confounders, and source context.
Null-result aware
Weakened paths are not re-promoted unless the changed discriminator is explicit.
Falsification-first
Strong ideas are paired with controls, readouts, and tests that could prove them wrong.
Thread-scoped memory
Drill-downs carry useful priors forward without leaking across unrelated topics.
Turn datasets into tested hypotheses and interpretable models.
Standard analytics tools rank models. Research Lab frames a dataset as competing explanations, runs an adaptive model tournament, preserves negative results, and returns interpretable equations or readable model structure when the data supports them.
Hypothesis-tested modeling
Every run is tied to a claim, method, result, and caveat.
Adaptive model tournament
Statistical tests, gradient boosting, and symbolic regression compete based on the question.
Glass-box discovery
When structure is recoverable, the output can be an equation or interpretable model, not just a score.
Negative results count
Rejected hypotheses are preserved as evidence so the next run searches smarter.
Symbolic regression proof point
Equations you can inspect.
The symbolic-regression stack recovered Kepler’s Third Law and the Rydberg Formula with perfect fit on standard benchmark tasks.
The learning loop changes measurable outcomes.
Same-provider workflow lift
Same-provider baseline. Better outcomes.
Against the same-provider direct baseline, Lumenais improved average composite reasoning quality by 48.6% on a 56-prompt live paired benchmark while improving grounding fit from 94.64% to 100%.
Governed memory
Useful context survives. Noise stays out.
In a 32-case live governed-memory benchmark, Lumenais recovered current reviewed project context with a 98.96% mean recall score, a 100% seeded memory-retrieval rate, and 0% control-user leakage across continuity, rejected-noise, superseding-update, and topic-isolation tasks.
Cross-domain transfer
Learning is most useful when it travels.
Across 150 governed-versus-baseline runs on five domain pairs, cross-domain transfer measured about 13% accuracy uplift over baseline.
Continuity you can inspect.
The Companion interface shows how governed memory feels in practice: prior decisions return, corrections can supersede stale facts, and symbolic-state telemetry makes continuity inspectable without pretending the visualization is proof of cognition.
See how companion learning is governed

Learning only matters if you can trust what changed.
FieldHash
Tamper-evident provenance for selected major artifacts and governance decisions. It helps reviewers see what evidence shaped an insight without exposing private internals.
Evidence: FieldHash adaptive spoofing campaign.
FieldHash overviewGnosis Engine
Bounded adaptation stays governable through static review, isolated testing, coherence checks, signed decisions, and rollback before sensitive changes can affect production behavior.
Gnosis overviewThinking resets.
Judgment compounds.
Read the technical brief to see the architecture, evidence posture, limitations, and governed learning loop in one place.
Qualified reviewers can request deeper architecture notes, benchmark methodology, ablation summaries, and trace examples.